New Publication: Simulating Algorithmic Personalization and Polarization
We are pleased to announce a new peer-reviewed publication by Ljubiša Bojić, co-authored with Velibor Ilić, Veljko Prodanović, and Vuk Vuković, published in Chinese Political Science Review.
The paper introduces the Recommender Systems LLMs Playground (RecSysLLMsP), an agent-based simulation framework designed to study how recommender systems and large language models jointly shape engagement, emotional dynamics, and polarization in social media environments.
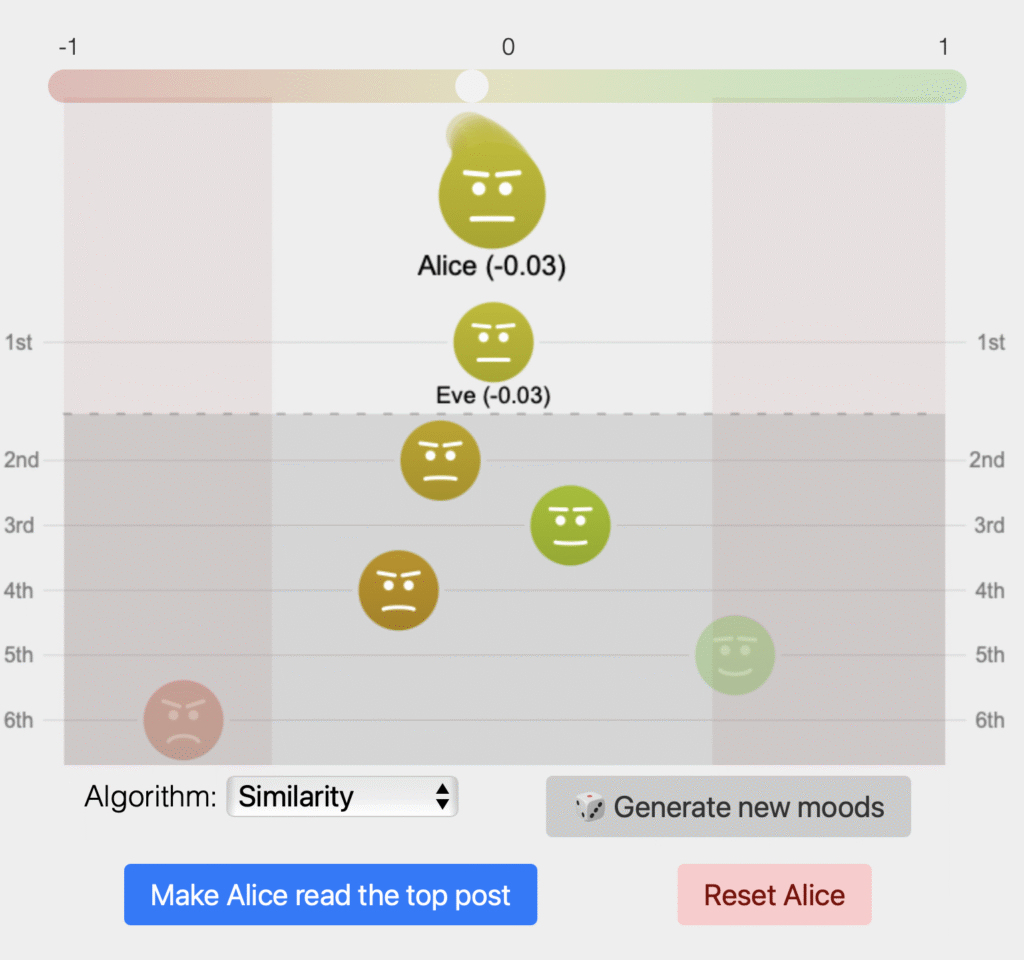
The study models a synthetic social media ecosystem with 100 agents grounded in real psychometric and demographic data. Agents interact through feeds with progressively increasing levels of personalization, while content is generated and adapted using large language models. This setup enables controlled observation of how algorithmic personalization affects collective behavior.
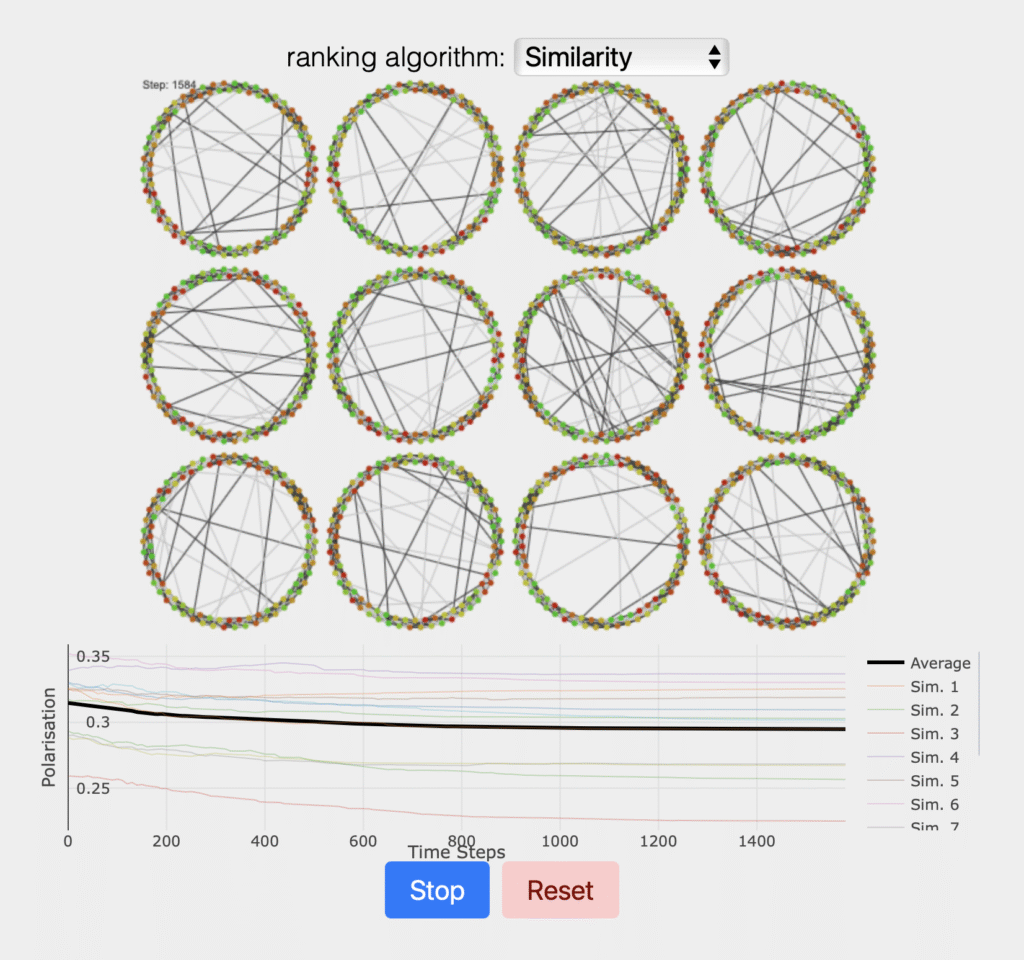
Key findings show that moderate personalization maximizes engagement, while full personalization significantly reduces content diversity and amplifies both structural and affective polarization. Network modularity increases sharply as personalization deepens, indicating the emergence of echo-chamber dynamics. At the same time, the simulation demonstrates that LLM-based agents can reproduce realistic patterns of emotional contagion and ideological clustering.
RecSysLLMsP provides a transparent and reproducible “digital laboratory” for testing recommender system designs and policy interventions before they are deployed at scale. The framework has direct relevance for research in computational social science, responsible AI, platform governance, and democratic communication.
Publication details:
An Agent-Based Simulation of Politicized Topics Using Large Language Models: Algorithmic Personalization and Polarization on Social Media
Chinese Political Science Review
DOI: 10.1007/s41111-025-00326-x